Vừa
qua, đội thi NEUDolphins đến từ khoa Toán Kinh tế, Trường Đại học Kinh
tế Quốc dân đã lọt vào top 5 đội xuất sắc nhất của Việt Nam và đạt thứ
hạng thứ 31 trên tổng số 679 đội thi tham dự cuộc thi Women in Data
Science do Đại học Stanford tổ chức.
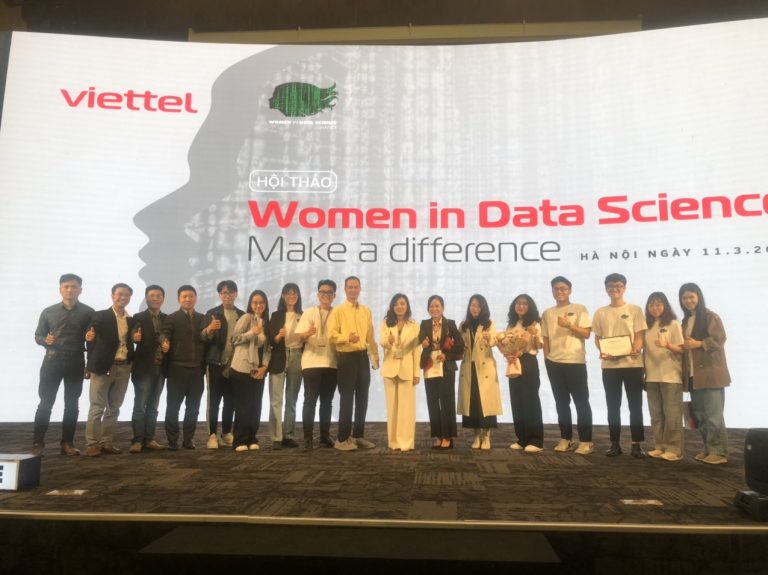
NEUDolphins đã lọt vào top 5 đội xuất sắc nhất của Việt Nam và đạt thứ hạng thứ 31 trên tổng số 679 đội thi
Đội
NEUDolphins đến từ khoa Toán Kinh tế, gồm bốn thành viên lớp Khoa học
dữ liệu trong Kinh tế và Kinh doanh (DSEB) khóa 62 đã lọt vào top 5 đội
xuất sắc nhất của Việt Nam và đạt thứ hạng thứ 31 trên tổng số 679 đội
thi tham dự. Đây là lần đầu tiên sinh viên chương trình DSEB tham dự một
cuộc thi về khoa học dữ liệu với quy mô lớn nhưng kết quả đạt được là
rất đáng khích lệ.
Women
in Data Science (WiDS) Datathon là cuộc thi do Đại học Stanford tổ chức
trên nền tảng Kaggle. Các đội thi là các chuyên gia dữ liệu trên toàn
thế giới, mỗi đội thi tối đa 4 người và tối thiểu 50% là nữ. Chủ đề cuộc
thi năm nay là: “Thích ứng với biến đổi khí hậu bằng cách cải thiện dự
báo thời tiết cực đoan”. Nhiệm vụ của các đội thi là dựa trên dữ liệu
quan sát trong lịch sử để xây dựng một mô hình dự đoán nhiệt độ không
khí trong 2 tuần tiếp theo tại các địa điểm khác nhau. Thứ hạng các đội
sẽ được xác định dựa trên độ chính xác khi so sánh kết quả dự đoán với
kết quả thực tế (sử dụng RMSE làm thước đo). Thử thách lớn nhất cho các
đội thi năm nay đó là dữ liệu được cho dưới dạng chuỗi thời gian, vốn
luôn là một bài toán hóc búa cho những người đam mê chinh phục trong
ngành khoa học dữ liệu.
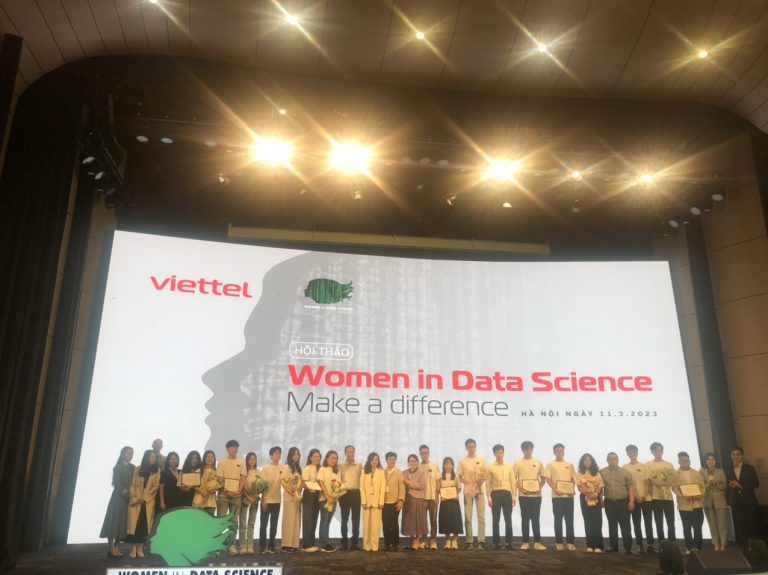
Đội NEUDolphins nhận kỷ niệm chương tại Tập đoàn Viễn thông Quân đội Viettel
Chia
sẻ về bí quyết để đạt được những thành tích như trên, nhóm NEUDolphins
với phương châm: “Vinh quang và may mắn sẽ chỉ mỉm cười với những người
nỗ lực nhất” đã không ngừng nghiên cứu nhiều hướng tiếp cận khác nhau
cho đề bài được đưa ra. Nhiều bước phân tích khám phá dữ liệu
(exploratory data analysis) sử dụng các phương pháp thống kê và phân
tích chuỗi thời gian đã được thực hiện nhằm giúp nhóm hiểu rõ về đặc
điểm dữ liệu, từ đó đề ra những chiến lược feature engineering và lựa
chọn các mô hình thích hợp để huấn luyện. Đội thi đã lựa chọn nhiều mô
hình để huấn luyện cùng lúc như Random Forest, các mô hình thuộc nhóm
Gradient Boosting như LightGBM, CatBoost, XGBoost và mô hình học sâu sử
dụng kiến trúc Transformer như TabNet… Mỗi mô hình sẽ phù hợp với các
bước feature engineering khác nhau cũng như đòi hỏi quá trình tinh chỉnh
siêu tham số kỹ càng. Sau cùng, nhóm sử dụng kỹ thuật model ensembling
để kết hợp dự đoán của nhiều mô hình và đưa ra dự đoán cuối cùng, đây
cũng chính là yếu tố quan trọng nhất đã giúp điểm số của NEUDolphins cải
thiện đáng kể.
Qua
cuộc thi, các thành viên đã gặt hái được nhiều kinh nghiệm thực tế với
các mô hình học máy, mô hình học sâu và có cho mình những bài học quý
báu trong phán đoán và xử lý dữ liệu. Chia sẻ sau cuộc thi, nhóm
NEUDolphins mong muốn có thể lan tỏa tinh thần ham học hỏi và niềm say
mê với ngành học tới các bạn sinh viên trong khoa Toán Kinh tế và cả
những bạn trẻ đang có hứng thú với data science “Dữ liệu không hề khô
khan, chúng luôn ẩn chứa những câu chuyện và ý nghĩa đặc biệt nếu ta
hiểu và biết cách gợi mở những góc nhìn bên trong”.
Bài và ảnh: Khoa Toán Kinh tế